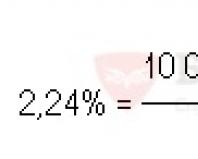Что такое статистическая значимость. Статистическая значимость
В конце нашего сотрудничества мы с Гэри Кляйном все же пришли к согласию, отвечая на основной поставленный вопрос: в каких случаях стоит доверять интуиции эксперта? У нас сложилось мнение, что отличить значимые интуитивные заявления от пустопорожних все же возможно. Это можно сравнить с анализом подлинности предмета искусства (для точного результата лучше начинать его не с осмотра объекта, а с изучения прилагающихся документов). При относительной неизменности контекста и возможности выявить его закономер ности ассоциативный механизм распознает ситуацию и быстро вырабатывает точный прогноз (решение). Если эти условия удовлетворяются, интуиции эксперта можно доверять.
К сожалению, ассоциативная память также порождает субъективно веские, но ложные интуиции. Всякий, кто следил за развитием юного шахматного таланта, знает, что умения приобретаются не сразу и что некоторые ошибки на этом пути делаются при полной уверенности в своей правоте. Оценивая интуицию эксперта, всегда следует проверить, было ли у него достаточно шансов изучить сигналы среды – даже при неизменном контексте.
При менее устойчивом, малодостоверном контексте активируется эвристика суждения. Система 1 может давать скорые ответы на трудные вопросы, подменяя понятия и обеспечивая когерентность там, где ее не должно быть. В результате мы получаем ответ на вопрос, которого не задавали, зато быстрый и достаточно правдоподобный, а потому способный проскочить снисходительный и ленивый ко нтроль Системы 2. Допустим, вы хотите спрогнозировать коммерческий успех компании и считаете, что оцениваете именно это, тогда как на самом деле ваша оценка складывается под впечатлением от энергичности и компетентности руководства фирмы. Подмена происходит автоматически – вы даже не понимаете, откуда берутся суждения, которые принимает и подтверждает ваша Система 2. Если в уме рождается единственное суждение, его бывает невозможно субъективно отличить от значимого суждения, сделанного с профессиональной уверенностью. Вот почему субъективную убежденность нельзя считать показателем точности прогноза: с такой же убежденностью высказываются суждения-ответы на другие вопросы.
Должно быть, вы удивитесь: как же мы с Гэри Кляйном сразу не додумались оценивать экспертную интуицию в зависимости от постоянства среды и опыта обучения эксперта, не оглядываясь на его веру в свои слова? Почему сразу не нашли ответ? Это было бы дельное замечание, ведь решение с самого начала мая чило перед нами. Мы заранее знали, что значимые интуитивные предчувствия командиров пожарных бригад и медицинских сестер отличны от значимых предчувствий биржевых аналитиков и специалистов, чью работу изучал Мил.
Теперь уже трудно воссоздать то, чему мы посвятили годы труда и долгие часы дискуссий, бесконечные обмены черновиками и сотни электронных писем. Несколько раз каждый из нас был готов все бросить. Однако, как всегда случается с успешными проектами, стоило нам понять основной вывод, и он стал казаться очевидным изначально.
Как следует из названия нашей статьи, мы с Кляйном спорили реже, чем ожидали, и почти по всем важным пунктам приняли совместные решения. Тем не менее мы также выяснили, что наши ранние разногласия носили не только интеллектуальный характер. У нас были разные чувства, вкусы и взгляды применительно к одним и тем же вещам, и с годами они на удивление мало изменились. Это наглядно проявляется в том, что каждому из нас ка жется занятным и интересным. Кляйн до сих пор морщится при слове «искажение» и радуется, узнав, что некий алгоритм или формальная методика выдают бредовый результат. Я же склонен видеть в редких ошибках алгоритмов шанс их усовершенствовать. Опять-таки я радуюсь, когда так называемый эксперт изрекает прогнозы в контексте с нулевой достоверностью и получает заслуженную взбучку. Впрочем, для нас в конечном итоге стало важнее интеллектуальное согласие, а не эмоции, нас разделяющие.
Статистическая значимость результата (p-значение) представляет собой оцененную меру уверенности в его «истинности» (в смысле «репрезентативности выборки»). Выражаясь более технически, p-значение ‑ это показатель, находящийся в убывающей зависимости от надежности результата. Более высокое p-значение соответствует более низкому уровню доверия к найденной в выборке зависимости между переменными. Именно, p-значение представляет собой вероятность ошибки, связанной с распространением наблюдаемого результата на всю популяцию. Например, p-значение=0.05 (т.е. 1/20) показывает, что имеется 5% вероятность, что найденная в выборке связь между переменными является лишь случайной особенностью данной выборки. Иными словами, если данная зависимость в популяции отсутствует, а вы многократно проводили бы подобные эксперименты, то примерно в одном из двадцати повторений эксперимента можно было бы ожидать такой же или более сильной зависимости между переменными.
Во многих исследованиях p-значение=0.05 рассматривается как «приемлемая граница» уровня ошибки.
Не существует никакого способа избежать произвола при принятии решения о том, какой уровень значимости следует действительно считать «значимым». Выбор определенного уровня значимости, выше которого результаты отвергаются как ложные, является достаточно произвольным. На практике окончательное решение обычно зависит от того, был ли результат предсказан априори (т.е. до проведения опыта) или обнаружен апостериорно в результате многих анализов и сравнений, выполненных с множеством данных, а также на традиции, имеющейся в данной области исследований. Обычно во многих областях результат p 0.05 является приемлемой границей статистической значимости, однако следует помнить, что этот уровень все еще включает довольно большую вероятность ошибки (5%). Результаты, значимые на уровне p 0.01 обычно рассматриваются как статистически значимые, а результаты с уровнем p 0.005 или p 0.001 как высоко значимые. Однако следует понимать, что данная классификация уровней значимости достаточно произвольна и является всего лишь неформальным соглашением, принятым на основе практического опыта в той или иной области исследования.
Как было уже сказано, величина зависимости и надежность представляют две различные характеристики зависимостей между переменными. Тем не менее, нельзя сказать, что они совершенно независимы. Говоря общим языком, чем больше величина зависимости (связи) между переменными в выборке обычного объема, тем более она надежна.
Если предполагать отсутствие зависимости между соответствующими переменными в популяции, то наиболее вероятно ожидать, что в исследуемой выборке связь между этими переменными также будет отсутствовать. Таким образом, чем более сильная зависимость обнаружена в выборке, тем менее вероятно, что этой зависимости нет в популяции, из которой она извлечена.
Объем выборки влияет на значимость зависимости. Если наблюдений мало, то соответственно имеется мало возможных комбинаций значений этих переменных и таким образом, вероятность случайного обнаружения комбинации значений, показывающих сильную зависимость, относительно велика.
Как вычисляется уровень статистической значимости. Предположим, вы уже вычислили меру зависимости между двумя переменными (как объяснялось выше). Следующий вопрос, стоящий перед вами: «насколько значима эта зависимость?» Например, является ли 40% объясненной дисперсии между двумя переменными достаточным, чтобы считать зависимость значимой? Ответ: «в зависимости от обстоятельств». Именно, значимость зависит в основном от объема выборки. Как уже объяснялось, в очень больших выборках даже очень слабые зависимости между переменными будут значимыми, в то время как в малых выборках даже очень сильные зависимости не являются надежными. Таким образом, для того чтобы определить уровень статистической значимости, вам нужна функция, которая представляла бы зависимость между «величиной» и «значимостью» зависимости между переменными для каждого объема выборки. Данная функция указала бы вам точно «насколько вероятно получить зависимость данной величины (или больше) в выборке данного объема, в предположении, что в популяции такой зависимости нет». Другими словами, эта функция давала бы уровень значимости (p-значение), и, следовательно, вероятность ошибочно отклонить предположение об отсутствии данной зависимости в популяции. Эта «альтернативная» гипотеза (состоящая в том, что нет зависимости в популяции) обычно называется нулевой гипотезой. Было бы идеально, если бы функция, вычисляющая вероятность ошибки, была линейной и имела только различные наклоны для разных объемов выборки. К сожалению, эта функция существенно более сложная и не всегда точно одна и та же. Тем не менее, в большинстве случаев ее форма известна, и ее можно использовать для определения уровней значимости при исследовании выборок заданного размера. Большинство этих функций связано с очень важным классом распределений, называемым нормальным.
Как вы думаете, что делает вашу «вторую половинку» особенной, значимой? Это связано с ее (его) личностью или с вашими чувствами, которые вы испытываете к этому человеку? А может, с простым фактом, что гипотеза о случайности вашей симпатии, как показывают исследования, имеет вероятность менее 5%? Если считать последнее утверждение достоверным, то успешных сайтов знакомств не существовало бы в принципе:
Когда вы проводите сплит-тестирование или любой другой анализ вашего сайта, неверное понимание «статистической значимости» может привести к неправильной интерпретации результатов и, следовательно, ошибочным действиям в процессе оптимизации конверсии. Это справедливо и для тысяч других статистических тестов, проводимых ежедневно в любой существующей отрасли.
Чтобы разобраться, что же такое «статистическая значимость», необходимо погрузиться в историю появления этого термина, познать его истинный смысл и понять, как это «новое» старое понимание поможет вам верно трактовать результаты своих исследований.
Немного истории
Хотя человечество использует статистику для решения тех или иных задач уже много веков, современное понимание статистической значимости, проверки гипотез, рандомизации и даже дизайна экспериментов (Design of Experiments (DOE) начало формироваться только в начале 20-го столетия и неразрывно связано с именем сэра Рональда Фишера (Sir Ronald Fisher, 1890-1962):

Рональд Фишер был эволюционным биологом и статистиком, который имел особую страсть к изучению эволюции и естественного отбора в животном и растительном мире. В течение своей прославленной карьеры он разработал и популяризировал множество полезных статистических инструментов, которыми мы пользуемся до сих пор.
Фишер использовал разработанные им методики, чтобы объяснить такие процессы в биологии, как доминирование, мутации и генетические отклонения. Те же инструменты мы можем применить сегодня для оптимизации и улучшения контента веб-ресурсов. Тот факт, что эти средства анализа могут быть задействованы для работы с предметами, которых на момент их создания даже не существовало, кажется довольно удивительным. Столь же удивительно, что раньше сложнейшие вычисления люди выполняли без калькуляторов или компьютеров.
Для описания результатов статистического эксперимента как имеющих высокую вероятность оказаться истиной Фишер использовал слово «значимость» (от англ. significance).
Также одной из наиболее интересных разработок Фишера можно назвать гипотезу «сексуального сына». Согласно этой теории, женщины отдают свое предпочтение неразборчивым в половых связях мужчинам (гулящим), потому что это позволит рожденным от этих мужчин сыновьям иметь такую же предрасположенность и произвести на свет больше своих отпрысков (обращаем внимание, что это всего лишь теория).
Но никто, даже гениальные ученые, не застрахованы от совершения ошибок. Огрехи Фишера досаждают специалистам и по сей день. Но помните слова Альберта Эйнштейна: «Кто никогда не ошибался, тот не создавал ничего нового».
Прежде чем перейти к следующему пункту, запомните: статистическая значимость — это ситуация, когда разница в результатах при проведении тестирования настолько велика, что эту разницу нельзя объяснить влиянием случайных факторов.
Какова ваша гипотеза?
Чтобы понять, что значит «статистическая значимость», сначала нужно разобраться с тем, что такое «проверка гипотез», поскольку два этих термина тесно переплетаются.
Гипотеза — это всего лишь теория. Как только вы разработаете какую-либо теорию, вам будет необходимо установить порядок сбора достаточного количества доказательств и, собственно, собрать эти доказательства. Существует два типа гипотез.

Яблоки или апельсины — что лучше?
Нулевая гипотеза
Как правило, именно в этом месте многие испытывают трудности. Нужно иметь в виду, что нулевая гипотеза — это не то, что нужно доказать, как, например, вы доказываете, что определенное изменение на сайте приведет к повышению конверсии, а наоборот. Нулевая гипотеза — это теория, которая гласит, что при внесении каких-либо изменений на сайт ничего не произойдет. И цель исследователя — опровергнуть эту теорию, а не доказать.
Если обратиться к опыту раскрытия преступлений, где следователи также строят гипотезы в отношении того, кто является преступником, нулевая гипотеза принимает вид так называемой презумпции невиновности, концепта, согласно которому обвиняемый считается невиновным до тех пор, пока его вина не будет доказана в суде.
Если нулевая гипотеза заключается в том, что два объекта равны в своих свойствах, а вы пытаетесь доказать, что один из них все же лучше (например, A лучше B), вам нужно отказаться от нулевой гипотезы в пользу альтернативной. Например, вы сравниваете между собой тот или иной инструмент для оптимизации конверсии. В нулевой гипотезе они оба оказывают на объект воздействия одинаковый эффект (или не оказывают никакого эффекта). В альтернативной — эффект от одного из них лучше.
Ваша альтернативная гипотеза может содержать числовое значение, например, B - A > 20%. В таком случае нулевая гипотеза и альтернативная могут принять следующий вид:

Другое название для альтернативной гипотезы — это исследовательская гипотеза, поскольку исследователь всегда заинтересован в доказательстве именно этой гипотезы.
Статистическая значимость и значение «p»
Вновь вернемся к Рональду Фишеру и его понятию о статистической значимости.
Теперь, когда у вас есть нулевая гипотеза и альтернативная, как вы можете доказать одно и опровергнуть другое?
Поскольку статистические данные по самой своей природе предполагают изучение определенной совокупности (выборки), вы никогда не можете быть на 100% уверены в полученных результатах. Наглядный пример: зачастую результаты выборов расходятся с результатами предварительных опросов и даже эксит-пулов.
Доктор Фишер хотел создать определитель (dividing line), который позволял бы понять, удался ли ваш эксперимент или нет. Так и появился индекс достоверности. Достоверность — это тот уровень, который мы принимаем для того, чтобы сказать, что мы считаем «значимым», а что нет. Если «p», индекс достоверности, равен 0,05 или меньше, то результаты достоверны.
Не волнуйтесь, в действительности все не так запутано, как кажется.

Распределение вероятностей Гаусса. По краям — менее вероятные значения переменной, в центре — наиболее вероятные. P-показатель (закрашенная зеленым область) — это вероятность наблюдаемого результата, возникающего случайно.
Нормальное распределение вероятностей (распределение Гаусса) — это представление всех возможных значений некой переменной на графике (на рисунке выше) и их частот. Если вы проведете свое исследование правильно, а затем расположите все полученные ответы на графике, вы получите именно такое распределение. Согласно нормальному распределению, вы получите большой процент похожих ответов, а оставшиеся варианты разместятся по краям графика (так называемые «хвосты»). Такое распределение величин часто встречается в природе, поэтому оно и носит название «нормального».
Используя уравнение на основе вашей выборки и результатов теста, вы можете вычислить то, что называется «тестовой статистикой», которая укажет, насколько отклонились полученные результаты. Она также подскажет, насколько близко вы к тому, чтобы нулевая гипотеза оказалась верной.
Чтобы не забивать свою голову, используйте онлайн-калькуляторы для вычисления статистической значимости:

Один из примеров таких калькуляторов
Буква «p» обозначает вероятность того, что нулевая гипотеза верна. Если число будет небольшим, это укажет на разницу между тестовыми группами, тогда как нулевая гипотеза будет заключаться в том, что они одинаковы. Графически это будет выглядеть так, что ваша тестовая статистика окажется ближе к одному из хвостов вашего колоколообразного распределения.
Доктор Фишер решил установить порог достоверности результатов на уровне p ≤ 0,05. Однако и это утверждение спорное, поскольку приводит к двум затруднениям:
1. Во-первых, тот факт, что вы доказали несостоятельность нулевой гипотезы, не означает, что вы доказали альтернативную гипотезу. Вся эта значимость всего лишь значит, что вы не можете доказать ни A, ни B.
2. Во-вторых, если p-показатель будет равен 0,049, это будет означать, что вероятность нулевой гипотезы составит 4,9%. Это может означать, что в одно и то же время результаты ваших тестов могут быть одновременно и достоверными, и ошибочными.
Вы можете использовать p-показатель, а можете отказаться от него, но тогда вам будет необходимо в каждом отдельном случае высчитывать вероятность осуществления нулевой гипотезы и решать, достаточно ли она большая, чтобы не вносить тех изменений, которые вы планировали и тестировали.
Наиболее распространенный сценарий проведения статистического теста сегодня — это установление порога значимости p ≤ 0,05 до запуска самого теста. Только не забудьте внимательно изучить p-значение при проверке результатов.
Ошибки 1 и 2
Прошло так много времени, что ошибки, которые могут возникнуть при использовании показателя статистической значимости, даже получили собственные имена.
Ошибка 1 (Type 1 Errors)
Как было упомянуто выше, p-значение, равное 0,05, означает: вероятность того, что нулевая гипотеза окажется верной, равняется 5%. Если вы откажетесь от нее, вы совершите ошибку под номером 1. Результаты говорят, что ваш новый веб-сайт повысил показатели конверсии, но существует 5%-ная вероятность, что это не так.
Ошибка 2 (Type 2 Errors)
Эта ошибка является противоположной ошибке 1: вы принимаете нулевую гипотезу, в то время как она является ложной. К примеру, результаты тестов говорят вам, что внесенные изменения в сайт не принесли никаких улучшений, тогда как изменения были. Как итог: вы упускаете возможность повысить свои показатели.
Такая ошибка распространена в тестах с недостаточным размером выборки, поэтому помните: чем больше выборка, тем достовернее результат.
Заключение
Пожалуй, ни один термин среди исследователей не пользуется такой популярностью, как статистическая значимость. Когда результаты тестов не признаются статистически значимыми, последствия бывают самые разные: от роста показателя конверсии до краха компании.
И раз уж маркетологи используют этот термин при оптимизации своих ресурсов, нужно знать, что же он означает на самом деле. Условия проведения тестов могут меняться, но размер выборки и критерий успеха важен всегда. Помните об этом.
Давайте рассмотрим некоторые тонкости практического использования линии тренда. Прежде всего надо выяснить, что определяет значимость этой линии. Ответ на этот вопрос двоякий: с одной стороны, значимость линии тренда зависит от срока ее действия, с другой стороны - от того, сколько раз она была проверена. Если, допустим, линия тренда выдержала восемь проверок, каждая из которых подтвердила ее истинность, то, без сомнения, она более значима, чем линия, которой цены касались всего три раза. Кроме того, линия, которая доказывала свою эффективность на протяжении девяти месяцев, намного важнее, чем та, что просуществовала девять недель или дней. Чем выше значимость линии тренда, тем больше ей можно доверять и тем большее значение будет иметь ее прорыв.
Линии тренда должны включать в себя весь диапазон цен дня
Линии тренда на столбиковых графиках должны вычерчиваться под или над столбиками, обозначающими весь диапазон колебаний цен за день. Некоторые специалисты предпочитают строить линии тренда, соединяя между собой лишь цены закрытия, но этот подход не вполне адекватен. Разумеется, цена закрытия является важнейшим ценовым значением за весь день, но, тем не менее, она представляет собой лишь частный случай динамики цен в рамках целого дня торгов. Поэтому при построении линии тренда принято учитывать весь диапазон колебаний цен за день (см. рис. 4.8).
Рис. 4.8 Правильно вычерченная линия тренда должна включать в себя весь диапазон колебаний цен за день торгов.
Что делать с незначительными прорывами линии тренда?
Иногда в течение дня цены прорывают линию тренда, но на момент закрытия все вновь возвращается на круги своя. Вот и приходится аналитику ломать голову: а был ли прорыв? (см. рис. 4.9). Нужно ли вычерчивать новую линию тренда, учитывающую новые данные, если небольшое нарушение линии тренда носило явно временный или случайный характер? На рисунке 4.9 изображена именно такая ситуация. В течение дня цены "нырнули" ниже восходящей линии тренда, но на момент закрытия вновь оказались выше нее. Надо ли в этом случае заново вычерчивать линию тренда?
К сожалению, тут вряд ли возможно дать какой-либо однозначный совет на все случаи жизни. Иногда таким прорывом можно пренебречь, особенно если последующее движение рынка подтверждает истинность первоначальной линии тренда. В некоторых случаях нужен компромисс, когда аналитик в дополнение к первоначальной вычерчивает новую, пробную линию тренда, которая наносится на график пунктиром (см. рис. 4.9). В этом случае в распоряжении аналитика находятся сразу две линии: исходная (сплошная) и новая (пунктирная). Как правило, практика показывает, что если прорыв линии тренда был сравнительно небольшим и происходил лишь в рамках одного дня, а на момент закрытия цены выровнялись и вновь достигли отметки над линией тренда, то аналитик может пренебречь этим прорывом и продолжать пользоваться исходной линией тренда. Как и во многих других областях анализа рынка, тут вернее всего полагаться на опыт и чутье. В подобных спорных вопросах они - ваши лучшие советчики.

Рис. 4.9 Иногда прорыв линии тренда в пределах одного дня ставит аналитика перед дилеммой: сохранять ли исходную линию тренда, если она по-прежнему верна, или вычерчивать новую? Возможен компромисс, при котором исходная линия тренда сохраняется, но на график пунктиром наносится новая линия. Время покажет, какая из них верней.
Проверка гипотез проводится с помощью статистического анализа. Статистическую значимость находят с помощью Р-значения, которое соответствует вероятности данного события при предположении, что некоторое утверждение (нулевая гипотеза) истинно. Если Р-значение меньше заданного уровня статистической значимости (обычно это 0,05), экспериментатор может смело заключить, что нулевая гипотеза неверна, и перейти к рассмотрению альтернативной гипотезы. С помощью t-критерия Стьюдента можно вычислить Р-значение и определить значимость для двух наборов данных.
Шаги
Часть 1
Постановка эксперимента- Нулевая гипотеза (H 0) обычно утверждает, что между двумя наборами данных нет разницы. Например: те ученики, которые читают материал перед занятиями, не получают более высокие оценки.
- Альтернативная гипотеза (H a) противоположна нулевой гипотезе и представляет собой утверждение, которое нужно подтвердить с помощью экспериментальных данных. Например: те ученики, которые читают материал перед занятиями, получают более высокие оценки.
-
Установите уровень значимости, чтобы определить, насколько распределение данных должно отличаться от обычного, чтобы это можно было считать значимым результатом. Уровень значимости (его называют также α {\displaystyle \alpha } -уровнем) - это порог, который вы определяете для статистической значимости. Если Р-значение меньше уровня значимости или равно ему, данные считаются статистически значимыми.
Решите, какой критерий вы будете использовать: односторонний или двусторонний. Одно из предположений в t-критерии Стьюдента гласит, что данные распределены нормальным образом. Нормальное распределение представляет собой колоколообразную кривую с максимальным количеством результатов посередине кривой. t-критерий Стьюдента - это математический метод проверки данных, который позволяет установить, выпадают ли данные за пределы нормального распределения (больше, меньше, либо в “хвостах” кривой).
- Если вы не уверены, находятся ли данные выше или ниже контрольной группы значений, используйте двусторонний критерий. Это позволит вам определить значимость в обоих направлениях.
- Если вы знаете, в каком направлении данные могут выйти за пределы нормального распределения, используйте односторонний критерий. В приведенном выше примере мы ожидаем, что оценки студентов повысятся, поэтому можно использовать односторонний критерий.
-
Определите объем выборки с помощью статистической мощности. Статистическая мощность исследования - это вероятность того, что при данном объеме выборки получится ожидаемый результат. Распространенный порог мощности (или β) составляет 80%. Анализ статистической мощности без каких-либо предварительных данных может представлять определенные сложности, поскольку требуется некоторая информация об ожидаемых средних значениях в каждой группе данных и об их стандартных отклонениях. Используйте для анализа статистической мощности онлайн-калькулятор, чтобы определить оптимальный объем выборки для ваших данных.
- Обычно ученые проводят небольшое пробное исследование, которое позволяет получить данные для анализа статистической мощности и определить объем выборки, необходимый для более расширенного и полного исследования.
- Если у вас нет возможности провести пробное исследование, постарайтесь на основании литературных данных и результатов других людей оценить возможные средние значения. Возможно, это поможет вам определить оптимальный объем выборки.
Часть 2
Вычислите стандартное отклонение-
Запишите формулу для стандартного отклонения. Стандартное отклонение показывает, насколько велик разброс данных. Оно позволяет заключить, насколько близки данные, полученные на определенной выборке. На первый взгляд формула кажется довольно сложной, но приведенные ниже объяснения помогут понять ее. Формула имеет следующий вид: s = √∑((x i – µ) 2 /(N – 1)).
- s - стандартное отклонение;
- знак ∑ указывает на то, что следует сложить все полученные на выборке данные;
- x i соответствует i-му значению, то есть отдельному полученному результату;
- µ - это среднее значение для данной группы;
- N - общее число данных в выборке.
-
Найдите среднее значение в каждой группе. Чтобы вычислить стандартное отклонение, необходимо сначала найти среднее значение для каждой исследуемой группы. Среднее значение обозначается греческой буквой µ (мю). Чтобы найти среднее, просто сложите все полученные значения и поделите их на количество данных (объем выборки).
- Например, чтобы найти среднюю оценку в группе тех учеников, которые изучают материал перед занятиями, рассмотрим небольшой набор данных. Для простоты используем набор из пяти точек: 90, 91, 85, 83 и 94.
- Сложим вместе все значения: 90 + 91 + 85 + 83 + 94 = 443.
- Поделим сумму на число значений, N = 5: 443/5 = 88,6.
- Таким образом, среднее значение для данной группы составляет 88,6.
-
Вычтите из среднего каждое полученное значение. Следующий шаг заключается в вычислении разницы (x i – µ). Для этого следует вычесть из найденной средней величины каждое полученное значение. В нашем примере необходимо найти пять разностей:
- (90 – 88,6), (91- 88,6), (85 – 88,6), (83 – 88,6) и (94 – 88,6).
- В результате получаем следующие значения: 1,4, 2,4, -3,6, -5,6 и 5,4.
-
Возведите в квадрат каждую полученную величину и сложите их вместе. Каждую из только что найденных величин следует возвести в квадрат. На этом шаге исчезнут все отрицательные значения. Если после данного шага у вас останутся отрицательные числа, значит, вы забыли возвести их в квадрат.
- Для нашего примера получаем 1,96, 5,76, 12,96, 31,36 и 29,16.
- Складываем полученные значения: 1,96 + 5,76 + 12,96 + 31,36 + 29,16 = 81,2.
-
Поделите на объем выборки минус 1. В формуле сумма делится на N – 1 из-за того, что мы не учитываем генеральную совокупность, а берем для оценки выборку из числа всех студентов.
- Вычитаем: N – 1 = 5 – 1 = 4
- Делим: 81,2/4 = 20,3
-
Извлеките квадратный корень. После того как вы поделите сумму на объем выборки минус один, извлеките из найденного значения квадратный корень. Это последний шаг в вычислении стандартного отклонения. Есть статистические программы, которые после введения начальных данных производят все необходимые вычисления.
- В нашем примере стандартное отклонение оценок тех учеников, которые читают материал перед занятиями, составляет s =√20,3 = 4,51.
Часть 3
Определите значимость-
Рассчитайте дисперсию между двумя группами данных. До этого шага мы рассматривали пример лишь для одной группы данных. Если вы хотите сравнить две группы, очевидно, следует взять данные для обеих групп. Вычислите стандартное отклонение для второй группы данных, а затем найдите дисперсию между двумя экспериментальными группами. Дисперсия вычисляется по следующей формуле: s d = √((s 1 /N 1) + (s 2 /N 2)).
Определите свою гипотезу. Первый шаг при оценке статистической значимости состоит в том, чтобы выбрать вопрос, ответ на который вы хотите получить, и сформулировать гипотезу. Гипотеза - это утверждение об экспериментальных данных, их распределении и свойствах. Для любого эксперимента существует как нулевая, так и альтернативная гипотеза. Вообще говоря, вам придется сравнивать два набора данных, чтобы определить, схожи они или различны.
 (1 оценок, в среднем: 5,00 из 5)
(1 оценок, в среднем: 5,00 из 5)